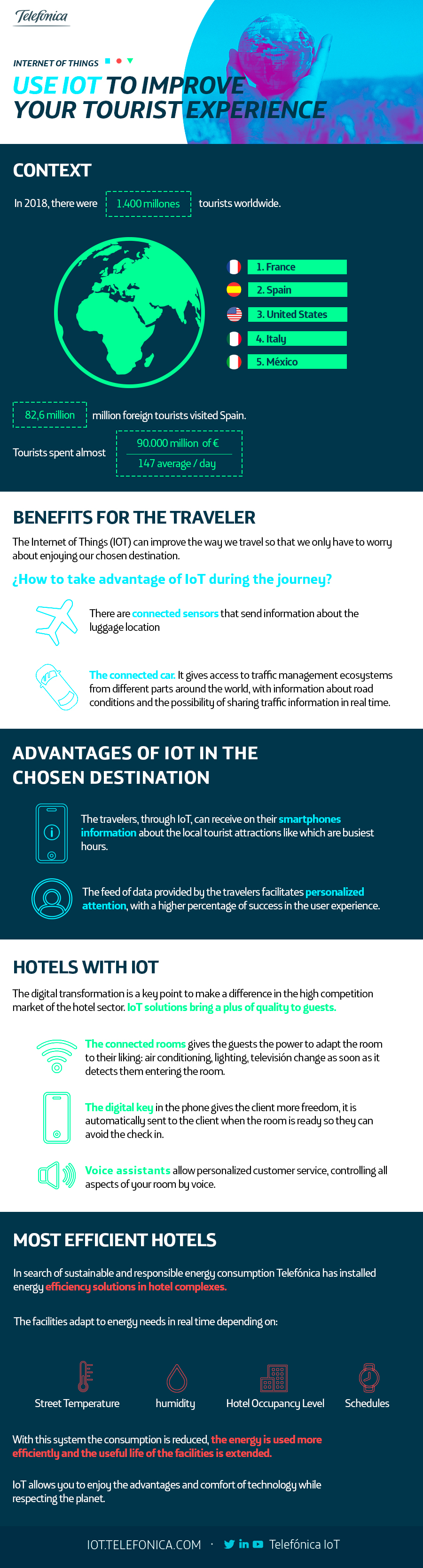
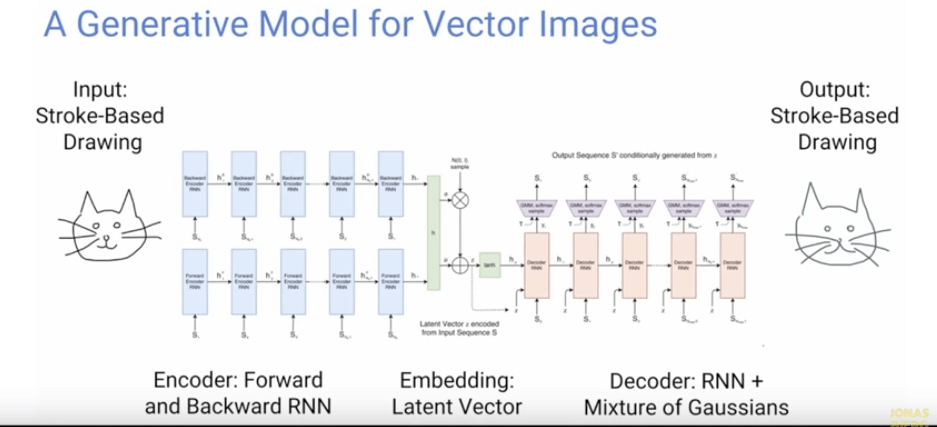
In a previous article we talked about how important it is to undertake a cultural transformation, that is, of individuals, whilst a company or sector undertakes a digital transformation of its processes and tools.
Today we present the success story of the Inter-American Development Bank (IDB), an international financial organization whose objective is to promote sustainable and responsible commercial growth in Latin America and the Caribbean.
This story begins when this organization detected a problem in its scope of influence. The advanced data analysis techniques offered by Big Data and Artificial Intelligence were not being fully exploited in the countries of Latin America and the Caribbean, especially in terms of growth and competitiveness for the private sector and efficiency for the public sector.
In order to reduce these limitations and develop the skills of sought-after profiles in this field, the IDB entrusted the LUCA Academy team with the design and production of a Spanish MOOC, a pioneer in its format and scope, with a strong focus on improving human capital and managing information in digital environments.
The first edition of the MOOC has been very well received, with more than 17,000 students registered in 17 countries. Due to this success, the second edition of the course has already been launched.
Because every transformation begins with education.
To carry out this project, LUCA was selected due to its leading position in the sector and due to its team of experts in all disciplines of Big Data and Artificial Intelligence, with extensive experience and knowledge of data projects in both the public and private sectors.
To stay up to date with LUCA, visit our Webpage, contact us and follow us on Twitter, LinkedIn o YouTube.