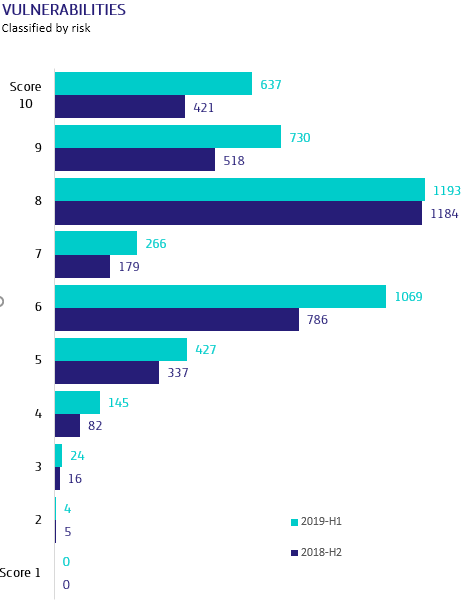
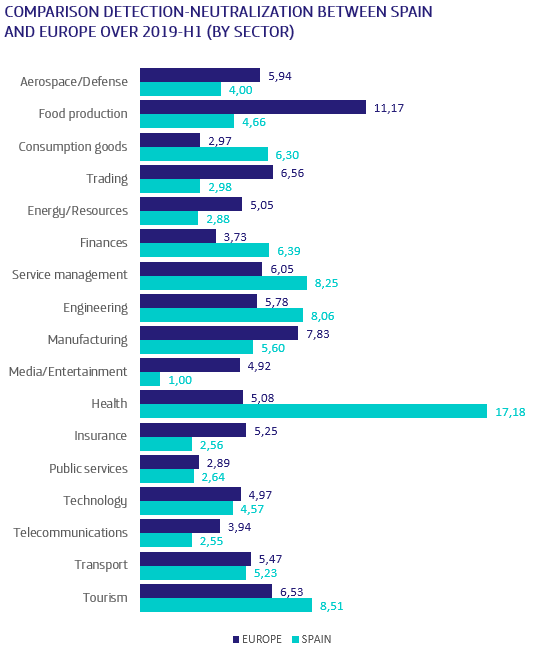
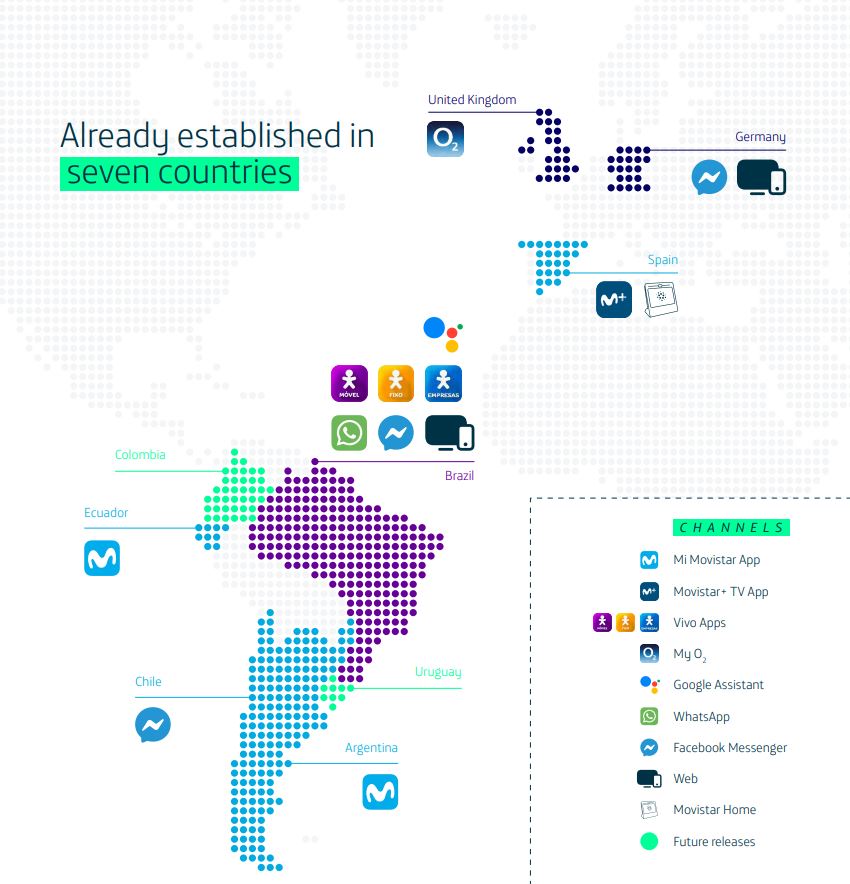
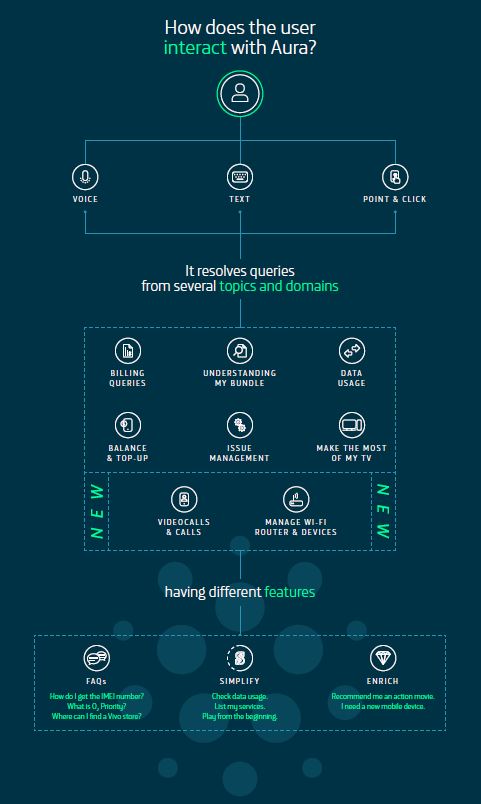
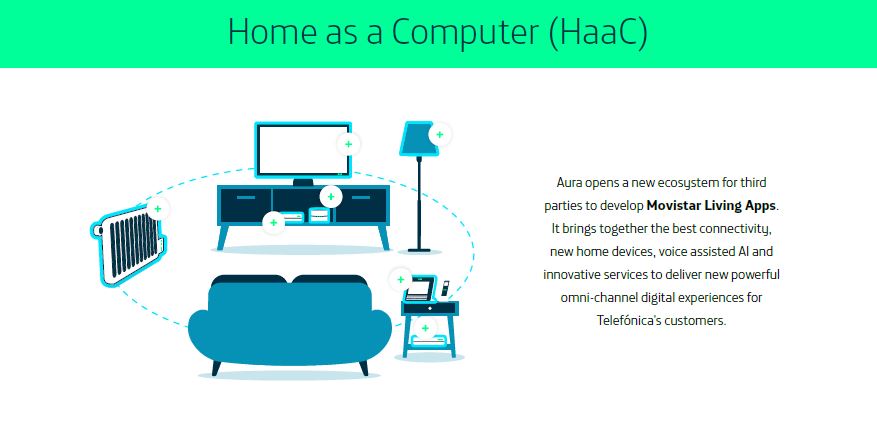
Telefónica has been introducing technology into its customers’ homes for years, and now it is taking a step further by implementing Artificial Intelligence at home, through Movistar Home and Movistar Living Apps. An entire ecosystem of devices and services that work through Aura, Telefónica’s Artificial Intelligence.
Movistar Living Apps are new experiences developed internally or by third parties that will enrich the way users make use of technology in their homes. They can be accessed through the television, the Movistar Home device, or the remote control.
Thanks to Movistar Living Apps, Telefónica is opening up a path of digital transformation through what they have named the “Aura Ecosystem”, the new technological platform for the home in which external partners can develop their Movistar Living Apps to offer new services related to home automation, travel, shopping, etc.
We turn homes into an intelligent and open to new experiences computer, creating unique moments with just one voice command.
Chema Alonso, Telefonica’s CDO
Some of the following partners have already joined this new experience, which can be used through Movistar Home and television, for example:
- Air Europa: Aura will help users check in for a flight, select their seat, add luggage, and it sends the boarding pass to their mobile phone.
- Atlético de Madrid: Aura will provide club members, who are Movistar customers also, with the option to transfer their season tickets so that there are no empty seats in the stadium.
- El Corte Inglés: Aura will offer products related to Movistar+ content. It will also offer customers the option of completing their purchase through their mobile phone.
In addition to these experiences, internal functionalities have also been developed such as Smart Wi-Fi, which lets you see which devices are connected at home or the list of devices on the Wi-Fi network, Movistar Cloud, where all the videos and photos stored in the cloud can be viewed on the television, and Movistar Car which shows the route a car is taking in real time, as well as sending periodic notifications to the customer about the condition of their vehicle.

This is just one example of how Telefónica is becoming increasingly significant to its customers and how it fulfils its responsibility to bring the best of technology and new cognitive skills to their lives, proving to be a telco which knows how to best anticipate the future.