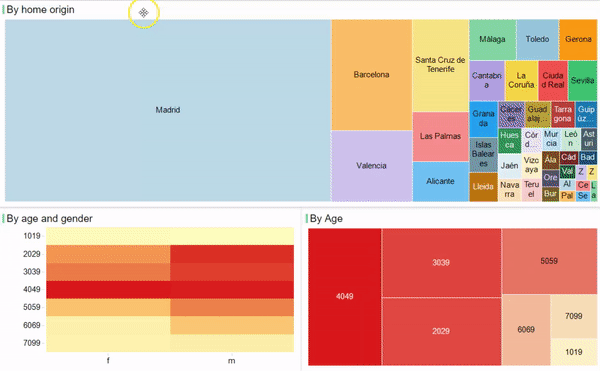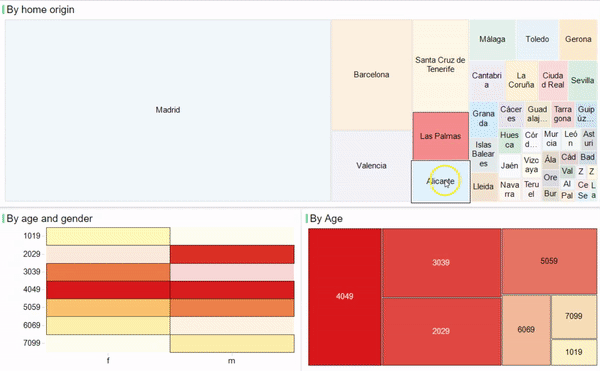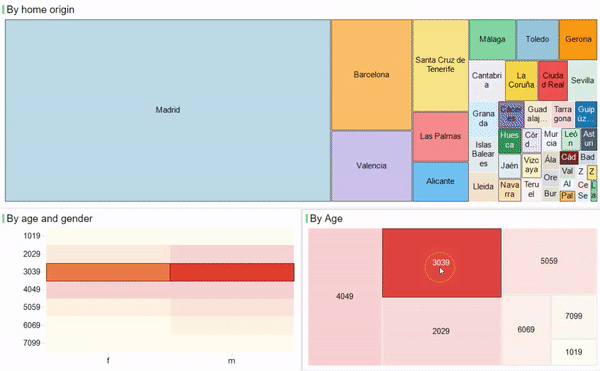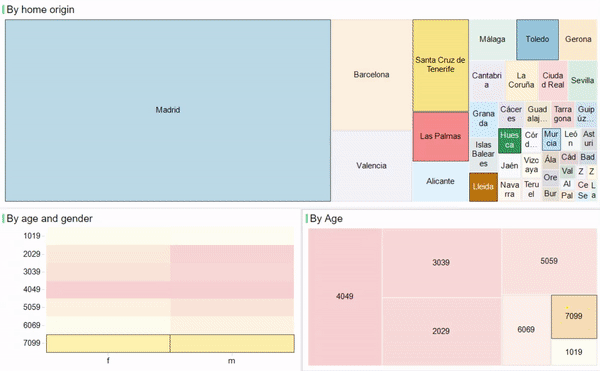
2016 has been the year when connectivity started to change driven by LPWA technologies and Personal IoT gains traction as a scenario where users are the main players. But other interesting technologies such as BlockChain, Virtual/Augmented Reality and Machine Learning are also emerging and growing quickly in the ecosystem. These are the trends that are setting the stage for 2017.
IoT Processes Technologies
Big Data analytics transforms everything
IoT means a huge amount of data and capturing, analysing and using those massive data sets is a real challenge. Big Data was born as a concept due to the inability to acquire, curate and analyse certain amounts of data within an acceptable time range. That gives us an idea of how broad Big Data could be. Actually, Big Data is a cross-cutting theme related to almost every field of IT. Shopping, healthcare, finance, information…IoT is immersed in and part of this ocean that is Big Data. From sensor data to information received from users, the range of information with which it works is intricately interrelated. Analytical algorithms and computing play a key role in making the information valuable and practical by filtering and organizing it. Scalability [1] is one of the biggest challenges on the horizon. But even with these difficulties, Big Data analytics are overwhelmingly utilized in global development projects [2], such as LUCA, the new Big Data services unit of Telefónica which enables its corporate clients to understand their data and encourages a transparent and responsible use of it by bringing companies closer to their customers and allowing them to optimize their entire operation. Step by step, all the information in the network is merging into Big Data, transforming everything.
Machine learning, true innovation in AI
Thanks to Machine learning programming, computers gain the ability to learn new ways to face new challenges more efficiently, using resources in smarter ways or even learning new tasks to complete. As the size and complexity of the data collected grows, there is an increasing need to go beyond efficiency improvements and automation regarding IoT. Machine learning is the process of automating the analytical data model and is a first step towards artificial intelligence applied to IoT. Likewise, because of its implications, machine learning is employed in a wide range of computing tasks where designing and programming explicit algorithms is unfeasible. Chatbots, for example, are a perfect example of machine learning. Chatbots are typically used in dialog systems for practical purposes: customer service, assistance or information acquisition. They are programmed to be richer in their responses, more efficient and more effective completing their tasks. The deeper is their interaction with the users, the better the results they are able to give in return. As an evolving technology, Natural Language Processing (or NLP) is a promising part of machine learning that assures more natural, fluent and efficient communication. IoT could harness this kind of technology to improve human-to-machine interaction, making it more sophisticated as well as more valuable. This important bridge will prove to be crucial.
The role of BlockChain in IoT
A BlockChain is a distributed database made up of blocks or strings designed to prevent modifications once data has been published [3]. The purpose is to store a continuously growing list of records which cannot be modified or revised. This has a number of very important implications in transaction systems and legal issues, as well as technological implications. According to some experts in the industry, BlockChain technology is the missing link to resolve scalability, privacy and reliability concerns in the IoT. According to Cisco, 50 billion devices are due to come online by 2020 [4]. How exactly can we track and manage billions of connected devices store the metadata that these devices produce and do it all reliably and securely? Blockchain is intended to address this problem by offering solutions that allow users a realistic, progressive and rapid IoT adoption. This technology can be used in tracking, enabling transactions and coordination between devices to be processed. This means significant savings to IoT industry manufacturers. It is an important decentralized approach that would eliminate single points of failure, creating a more resilient ecosystem for devices to run on, while also making consumer data more private. This will open new possible scenarios where there have never been transactions before.
Security on Internet of Things
There is no way to talk about the IoT without addressing one of the most sensitive issues: security. Cybersecurity has always been an especially crucial concern on the Internet. It generates a great deal of interest among users and major concerns among entrepreneurs, and security experts work day and night to ensure that network is safe for both of them. Recent attacks on various companies and services that have compromised users’ security by making sensitive information available to hackers demonstrate that security is more important than ever in IoT. According to some experts’ predictions, by 2017 the most critical vulnerabilities will continue to exist on the network. In fact, the industrial IoT will also become more vulnerable to cyberattacks in 2017 as its informational and operational technologies continue to converge [5]. At Telefónica, we care about these matters. We work hard with other security experts, such as Symantec, to guarantee protection. Mobile devices will emerge as an even greater personal and corporate security concern. But at the same time, industry must react to that concern by investing more time, more resources and more money into protecting our data. This involves changing paradigms and technologies, reinforcing those we already have and learning more about cybercriminals. Initiatives in IoT security like Trusted Public Key Infrastructure or Security Monitoring like Vamps and CyberThreats, examples of solutions that Telefónica provides, would help to assure this.
IoT Connectivity Technologies
LPWA expansion to harness the growing IoT
In 2015, we witnessed LPWA, as a group of technologies specialized for interconnecting devices with low-bandwidth connectivity, focusing on range and power efficiency, finally became a mature ecosystem. In 2016, its use in telecommunications has marked the expansion of these technologies. In 2017, LPWA will serve as a core support in the expansion of the IoT solutions. A “low power wide area” network is wireless network technology used to interconnect devices with low-bandwidth, focusing on long ranges and low power consumption rates. This means a wider range for M2M and IoT applications, both of which are constantly constrained by budgets, leading to better options for industrial and commercial applications. Hence, LPWA is being used for Smart Cities and buildings, industrial applications and transportation. But those are not the only areas suitable for harnessing the growth of the IoT. According to one analysis [6], the LPWA market will grow at a “compound annual growth rate”, or CAGR, of 90% between 2017 and 2022. Starting this coming year, the low cost of new chipsets designed for this kind of technologies would bring the massification of IoT. Millions of devices connected is an essential part that makes IoT what it is.
Comprehensive Smart Cities
The future of urbanism lies in the Smart Cities, places where infrastructures will provide an adequate standard of living. Smart cities are the flagships of sustainable solutions, responsiveness and efficient time management. The IoT is key in this conceptualization of everything connected and every single technology working together to improve the life of citizens, or Netizens (from Internet + Citizens [7]). These natural inhabitants of both, the web and Smart Cities, are actively involved in Internet projects, online communities and social improvements associated with the Internet. Examples such as the FIWARE community [8] shows what we can expect from an adequate definition of Smart Cities. This is an “independent open community with the will to build an open sustainable ecosystem around public, royalty-free and implementation-driven software platform standards that will ease the development of new Smart Applications in multiple sectors”. The FIWARE ecosystem is intended to set a standard in smart applications for Smart Cities, laying the groundwork for quick and efficient development.
Connected assets and valuable tracking
Asset monitoring is a subject which has developed considerably in recent years. While barcodes and RFID tags marked asset tracking, which is currently immersed in IoT, connected tracking is much more efficient, allowing for real-time monitoring and many more features. We can not only trace a product but specific information can now be obtained from different sensors. For example, thanks to a wide variety of add-ons to monitor temperature, humidity or similar parameters, we can achieve real-time control of any kind of assets with additional value added functionalities. There are endless possibilities, from quality control to ensuring the conditions or safety of our assets just at hand. Technologies as the Telefónica multi-sensory geolocation solution, showed at the past MWC, in Barcelona, would provide users with the best indoor location. A successful example is GTX. This company developed a system that enables relatives and caregivers to easily bring their patients back home thanks to the integration of positioning and IoT communication. From the industrial point of view, these solutions also offer a vital amount of valuable information when making market decisions, usability improvements or user preferences, among many other things.
IoT Trends in Consumer Products
Connected cars, evolved driving
Autonomous cars are in the future of more and more automotive companies. These vehicles mean a leap forward for the driving experience. But for such a leap to become a reality, vehicles must be connected to the network. As the IoT is reaching the automotive industry, we can find more and more interconnections between devices and our vehicles. With cars capable of getting information from the Internet, the IoT will play an essential role in connected cars. For example working with algorithms in real time to avoid collisions, thus improving road safety, will be a crucial part of autonomous cars implementation in society; also, users will take advantage of IoT getting driving maps with points of interest or keeping them connected while driving. But much remains to be developed. Currently, the European Commission is continuing its work on a draft law to cover the existence and legal scope of all the nuances related to autonomous driving [9]. But a Smart City cannot be understood without cars connected to the network and the vast amount of information that this entails. These vehicles will be a part of its essential fabric, and next year we will begin to see the dawn of these cars.
Virtual, Augmented and Merged Realities
From a certain vantage point, virtual reality and IoT are two of the most important technologies from the last decade. In the first half of 2016 alone, an estimated $1.1 billion was invested in virtual reality [10]. In business and industry, AR can bring several advantages in maintenance of heavy machinery, helping in complicated assignments, or keeping a detailed and visual task list in real time. Also, it will allow better monitoring of work and workers, as well as trace delivery orders and their completion in a glance. This make the work flow easier, quicker and more efficient. The heavy machines manufacturer, Caterpillar, uses several IoT elements like sensors in the machinery, Big Data and a cloud backend to deliver a full-blown system with AR. This provides interesting solutions as several interfaces, operational and technical assistance and, also, asset management due to an AR device like a mobile phone or special glasses. When we talk about the IoT plus augmented reality or virtual reality, one concept is inevitable: “telepresence”, the fact of being there without being there, or being far away. This virtual presence is beginning to be exploited with keener interest every day, and it plays a crucial role in Smart Cities, where Netizens will be able to access more services from anywhere. The user’s intimate interaction with the world created under the premises of virtual reality signals an advance in social interactions as well as interactions with the network. It is still too early to see how the implementation of both technological ecosystems will develop, but their future is very promising. And next year we will begin to see what they are capable of.
Your own Internet of Things
IoT sets the stage for the evolution from “user” to “Netizen”. Internet of Things is both a driving force and a tool that is spearheading a change, in which people will go from accessing network services to being truly connected. Areas like personal medicine, applications and wearables, instant access to cloud services, our own “domotic” relationship with a smart home, autonomous car or Smart City… all of them are unavoidable individual facts, expressions of personal IoT that will guide the evolution of the ecosystem towards a more practical and adapted reality. Nowadays, health is already benefiting from personal IoT, but we foresee other personal IoT scenarios beyond medicine, such as wellness, lifestyle and peace of mind, with strong user interactions. As said before, we are already experiencing some of the advantages of personal IoT. But in the forthcoming years, we will see it fusing rapidly and becoming a natural part of our day-to-day lifestyle.
Citations
[1] “Clouds for Scalable Big Data Analytics”, Talia, D. Nov 30, 2016.
[2] “Harnessing the Internet of Things for Global Development”, Cisco. Nov 30, 2016.
[3] “Bitcoin: A Peer-to-Peer Electronic Cash System”, Nakamoto, S. Nov 30, 2016.
[4] “The Internet of Things How the Next Evolution of the Internet Is Changing Everything”, Evans, D., CISCO. Nov 30, 2016.
[5] “What Lies Ahead? Cybersecurity Predictions for 2017.” Chain Storage Age. Nov 30, 2016.
[6] “Low Power Wide Area Network Market Report 2016-2022 | Infoholic Research.” Nov 30, 2016.
[7] “CMC Magazine: Call for Articles on Netizen” 1996.
[8] “FIWARE.” Nov 30, 2016.
[9] “Automated vehicles in the EU”, EU Parliament, Nov 30, 2016.
[10] “AR/VR Investment Hits $1.1 Billion Already in 2016” Digi-Capital. Nov 30, 2016.