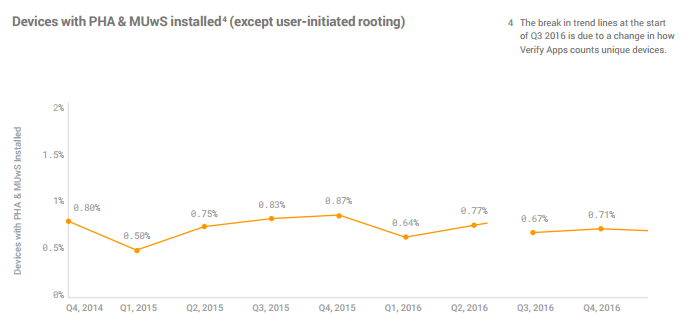
Just a few months ago, the capital of the Valencian community hosted the biggest party of the year: Las Fallas de Valencia. Every year from the 15th until the 19th of March, Valencia celebrates the arrival of spring with an event that is world-renowned.
In the weeks leading up to Las Fallas, the Valencian people working to create over 700 card statues that are linked to prominent characters from their history. The main event of the festivities is the powder that lights up the city on the night of the 19th of March, when all of the memorable parts of their history are lit up by the so-called “Cremà.” The festival has reached such high levels of popularity that in November 2016, UNESCO placed it on their list of intangible cultural heritage.
 |
| Figure 1: Las Fallas de Valencia attract more than one million people each year. |
Over the course of the past year, we worked with the Valencian City Council to help them understand and give meaning to the tourism that they receive each year during Las Fallas. We used CARTO (the leading business in interactive maps) to visualize the insights that we discovered through our data analysis.
Our analysis firstly allowed us to compare the number and demographic profile of the visitors from 2014 and 2015. Not only could we analyze how people moved around the city during the event but we could also capture information to create a comparison between national and international tourism.
Like the two years we analyzed, the 2016 festival was also a definitive success. The festival welcomed over one and a half million people with a spending of 500 million euros.