Content written by Daniela Perrotta, ISI Foundation researcher and UN Global Pulse fellow and Enrique Frias-Martinez, Researcher, Telefonica Research, Madrid. Originally posted on the UN Global Pulse blog.
Nowadays, thanks to the continuous growth of the transport infrastructures, millions of people travel every day around the world, resulting in more opportunities for infectious diseases to spread on a large scale faster than ever before. In this blog, Enrique Frias explains how mobile data was used to map and predict the spread of Zika in Colombia.
A brief history of pandemics…
Between 1918 and 1920, due to the special circumstances of World War I, such as overcrowded camps and hospitals, and soldiers piled in trenches or in transit every day, the Spanish Flu killed between 20 and 100 million people (more than the war itself) resulting perhaps in the most lethal pandemic in the history of humankind. The question that then arises naturally is the following: what if an equally virulent and deadly virus would hit today’s highly-connected world where you can easily reach most places in less than a day’s journey? Indeed, this prospect raises a growing global concern towards the next potential pandemic: when and where it might strike, and whether practitioners and scientists are prepared to respond and prevent the disastrous consequences of widespread spreading of a new disease. The search for the answer to this question, however, does not come without challenges since the emergence (or re-emergence) of human infectious diseases is continuous, variable and remarkably difficult to predict.
Just recently, between 2015 and 2016, the Americas experienced a large-scale outbreak of Zika that, until then, was considered a neglected tropical vector-borne disease with only local outbreaks over the years, since the virus responsible for the infection was first identified in Uganda in 1947. However, this represents only one of the latest global public health threats that has once again highlighted the urgent need for accurate data on human mobility and modelling of mobility processes in order to timely assess the spatial spread of infectious diseases and allow for rapid interventions and appropriate control measures to reduce the overall impact of diseases.
Traditional Methods vs Mobility Data
In developed countries, population movements are traditionally observed by national statistical institutes through costly and non-scalable techniques, such as census surveys, aimed at gathering information on the way people usually move on a daily basis. However, such datasets may be inadequate due to lacking spatial resolution or updates, not allowing them to encompass the rapid evolution of travel patterns and often limiting the potential impact of many studies. Moreover, this information may be partially or completely unavailable in developing countries.
Mobility models help by leveraging the fundamental laws of physics to synthetically infer population movements according to parametric forms, such as the laws of gravity and radiation. However, these require good calibration data and their performance significantly depends on the specific geographical setting and modelling assumptions.
To overcome these limitations, more and more sources of data and innovative techniques are used to detect people’s physical movements over time, such as the digital traces generated by human activities on the Internet (e.g. Twitter, Flickr, Foursquare) or the footprints left by mobile phone users’ activity. In particular, cellular networks implicitly offer a large ensemble of details on human activity, incredibly helpful for capturing mobility patterns and providing a high-level picture of human mobility.

One powerful collaboration…
In this context, a collaborative effort began between Telefonica Research in Madrid (Spain), the Computational Epidemiology Lab at the ISI Foundation in Turin (Italy) and UN Global Pulse (an innovation initiative of the United Nations). This collaboration is currently investigating the human mobility patterns relevant to the epidemic spread of Zika at a local level, in Colombia, mainly focusing on the potential benefits of harnessing mobile phone data as a proxy for human movements. Mobile phone data is defined as the information contained in call detail records (CDRs) created by telecom operators for billing purposes and summarizing mobile subscribers’ activity, i.e. phone calls, text messages and data connections. Such “digital traces” are continuously collected by telecom providers and thus represent a relatively low-cost and endless source for identifying human movements at an unprecedented scale.
In this study, more than two billion encrypted, aggregated and anonymized calls made by around seven million mobile phone users in Colombia have been used to identify aggregated population movements across the country. To assess the value of such human mobility derived from CDRs, the data is evaluated against more traditional methods: census data, that are considered as a reference since they ideally represent the entire population of the country and its mobility features, and mobility models, i.e. the gravity model and the radiation model, that are the most commonly used today. In particular, the gravity model assumes that the number of trips increases with population size and decreases with distances, whereas the radiation model assumes that the mobility depends on population density.
What does the analysis involve?
The first step is to reconstruct a mobility network for each method to describe the flows of people travelling daily among departments of Colombia. It is worth noting that in principle finer geographical resolutions might be used, but if on the one hand CDRs data allow to potentially go down to the level of mobile phone towers, on the other hand census data are generally aggregated to a wider spatial resolution, thus also hindering the use of mobility models.
Each mobility network is statistically analysed in terms of the structural and topological properties and accurately compared with the mobility network generated by the census data in order to evaluate the main similarities and differences. On average, trips are concentrated in the western part of the country, including some connections to the Archipelago of San Andres, Providencia y Santa Catalina and a few links to the south, thus reflecting the spatial distribution of the approximately 47 million people that live in Colombia. In this case, from the networks’ point of view, the gravity model is not able to reproduce the mobility of census data as flows are strongly underestimated. On the other hand, the mobility determined by the radiation model and mobile phone data showed a comparable performance with high correlations and similarities with census data, thus successfully representing the mobility among departments in Colombia.
The next step is to assess the predictive power of each mobility network in the application to the study of Zika. Colombia was the second country, following Brazil, to have experienced a large-scale Zika outbreak in Latin America with over 100 thousand cases reported between October 2015 and July 2016, of which about 9% were laboratory confirmed. However, the burden of the epidemic might have been strongly overlooked because of several issues in reporting, mainly due to the clinical similarities of mild symptoms associated with Zika infection, asymptomatic cases, limited sentinel sites and medically unattended cases.
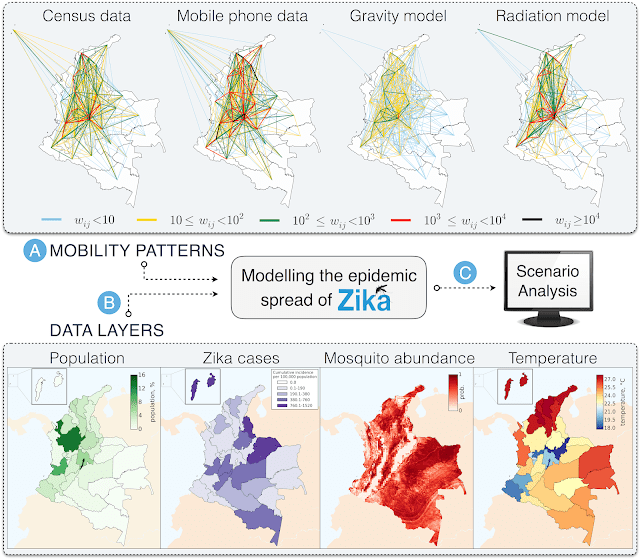
In this study, a metapopulational mathematical approach is adopted in order to explicitly simulate the epidemic spread of the disease as governed by the transmission dynamics of the Zika virus through human-mosquito interactions and promoted by the population movements across the country. This modelling approach allows us to represent the population divided into “subpopulations”, corresponding to defined geographical units (i.e. departments) connected by mobility flows, in which the infection dynamics occur according to a compartmental classification of the individuals based on the various stages of the disease. Given the same modelling settings (i.e. initial conditions and parameters), this approach allows us to perform numerical simulations of the spatio-temporal evolution of the epidemic spread of the disease by integrating one mobility network at a time. One can then ultimately assess their predictive power by comparing the simulated epidemic profiles with the Zika case data officially reported by the Instituto Nacional de Salud (INS) in Colombia.
However, this is not an easy task since, in the case of vector-borne diseases like Zika, several other factors beyond human mobility contribute to the epidemic spread of the infection. In fact, the local environment and climate are key factors that regulate the spatial and seasonal variability of the presence of the Aedes mosquitoes, primarily responsible for the transmission of the Zika virus. For example, the country’s capital, Bogotà, is not at risk for autochthonous Zika virus transmission because it is situated at an average altitude of 2,640 metres above sea level with an average monthly air temperature of 18°C, thus not favouring the presence of mosquitoes. Indeed, no confirmed cases of Zika have been reported in Bogotà.
Looking forward…
Therefore, further modelling efforts must be employed to account for all those ingredients that are necessary to provide a more realistic representation of the epidemic progression. This would involve following the same methodology adopted in recent state of the art approaches to Zika modelling, the model would integrate detailed data on the spatial heterogeneity of the mosquito abundance and the consequent exposure of the population to the disease, as well as detailed data on the population and the Zika cases. Indeed, this approach would allow the exploration of different epidemic scenarios and the comparison of the epidemic outcome provided by the integration of the various human mobility patterns to finally identify the potential impact of using the mobility derived from mobile phones to inform epidemic models and help public health authorities in planning timely interventions.
Don’t miss out on a single post. Subscribe to LUCA Data Speaks.