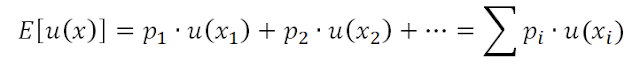
- Option A: I give 1,000 € to you with a probability of 100%.
- Option B: Let’s leave it to heads or tails: if it’s heads, you will win 2,000 € but if it’s tails, you will win nothing.
- Option A: You pay 1,000 € for the fine with a probability of 100%.
- Option B: You flip a coin to decide it: if it’s heads, you will pay 2,000 € for the fine but if it’s tails, you will pay nothing.
According to the expected utility theory, you will always choose the option that maximizes decision utility

If we were 100 % rational, by using this formula we would always know what to do at any time and how to take the ideal decision. For this purpose, we would only need to calculate the probability of each decision, its utility, and then take the decision that maximizes the expected value. Unfortunately, humans are not rational decision-making machines. We are not “homo economicus” with the ability to perform a perfect cost-benefit analysis and subsequently to choose, completely objectively, optimal results. Leaving games of luck behind, the nice Expected Utility Theory engages two big errors when we apply it to our everyday life:
- We are awful at estimating the chance of winning.
- We are awful at estimating income value.
While the expected value for option B is:
Both values are identical! Therefore, purely from a rational point of view,
both should be equally important to us. What about the second scenario?
In this case, the expected value for option A is:
While the expected value for option B is:
Once again, they are identical. Consequently, once again, it would be the same to choose one over the other. So, why do most of the people choose option A in the first case and option B in the second scenario, instead of choosing any of them? Because we are not purely rational!
- We would rather win a small but sure income, than a potential great income. As the saying goes: “a bird in the hand is worth two in the bush”.
- However, we detest sure small losses and would rather have a potential great loss. That is to say, we feel aversion to losses, so we assume the risk rather than lose.
“outweighs”.
Indeed, win satisfaction is far lower than the pain of grief. It’s quite easy to understand it: if you go out with 100 € but you lose 50, your subjective assessment of this loss is higher than if you go out with no money and you find 50 €, even if, objectively, such incomes are equal. In both cases you come back home with 50 €, but the process is not at all indifferent to you.
The following mathematical curve shows graphically the basis of the Prospect Theory, developed by Kahneman and Tversky:

This curve lists three essential cognitive characteristics of the Prospect
Theory, related to System 1:
- It’s not a straight (or concave) line, as expected from the Utility Theory.
Interestingly, it is like an S, which shows that awareness about incomes and losses tends to diminish: we tend to overestimate the small likelihoods and underestimate the great ones. - It is also surprising that both curves are not symmetric. The slope changes steeply on the point of reference due to the loss aversion: you react more strongly to a loss than to an –objectively equivalent– income. Indeed, this value is estimated to be 2-3 times stronger.
- Finally, options are not assessed on the basis of its result, but on the basis of the point of reference. If you have a capital of 1,000.00 € in the bank, you will be happier if you receive an additional amount of 1,000.00 € than if you already have 1,000,000.00 € in the bank. They are the same 1,000.00€, but the point of reference is different: that’s why you don’t appreciate them in the same way. It’s the same for losses: I’m sure that a loss of 1,000.00 € doesn’t impact you in the same way if you already have 2,000.00 € than if you have 1,000,000 €, right?
- We don’t assess objectively losses and incomes.
- We are swayed by the point of reference and loss aversion.
information is presented:
- 1st hypothesis: when two investment options on information security measures are positively presented, you will choose that one with greater certainty.
- 2nd hypothesis: when two investment options on information security measures are negatively presented, you will choose that one with less certainty.
data, reputation and time losses included). Which of the following packages, A or B, would you choose in each scenario?
- 1st scenario: options positively presented:
- Package A: you will certainly save 200,000.00 € of assets.
- Package B: there is a 1/3 likelihood of saving 600,000.00 € of assets and a 2/3 likelihood of not saving anything.
- 2nd scenario: options negatively presented:
- Package A: you will certainly lose 400,000.00 € of assets.
- Package B: there is a 1/3 likelihood of not losing anything and a 2/3 likelihood of losing 600,000.00 € of assets.
As you may observe, they are the first two scenarios proposed, but reformulated in terms of security decisions. Although A and B packages in both scenarios lead to the same expected utility, according to the Prospective Theory, in practice most of the security managers would choose package A from the first scenario (it’s better to save something certainly than to take the risk of not saving anything) and package B from the second one. However, an experience showed that in the second scenario both packages were chosen, with a bias towards package A.How important are these results in our everyday life? It’s impossible to list all the potential attacks existing and to calculate their probability and impact according to the traditional risk assessment formula. Therefore, you must be on guard against the mental processes that keep you away from optimal decisions:
- Depending on your attitude, risk-seeking or risk-avoidance, you tend to react one way or another, so bridging your rationality. Risk-seeking persons will choose options B. In practice, we tend to choose certain options when we face profits, in the same way we choose risky options when we face losses. That’s why, before taking a security decision, stop and ask yourself: How this option is being raised, as a profit or a loss? How do I tend to react when facing such scenarios? Do I tend to be risk-seeking or risk-avoidance? Who is taking the decision, System 1 or System 2?
- Thus, when presenting an investment option before the committee or the managers, you can do it from a positive or negative framework. In the first case, just raise profit certainty and keep away probabilities and risk. In the second case, instead of raising a sure loss (even though small), just raise the possibility of not losing (even if you risk a big loss) and point its high probability out.
- When framing a security investment, use the desire of earning with certainty. Instead of presenting this security investment as the expected protection against hypothetical threats that could not come into being, just focus on certain and unquestionable profits: a better reputation, customer’s reliability, efficient processes and operations, regulation compliance, etc. Try to drive the discussions to profits and talk about glaringly obvious matters. Seek sure profits and keep you away from possibilities and uncertainties.
- As security engineer or “defenders”, you are a good friend of Losses. In short, whatever you do, you will lose: if attacks are successful, you lose; if there is no proof of successful attacks, does it mean that you won? No, it doesn’t, so you will be told that you spent too much on security: you have lost again. Nobody said that working in cybersecurity was easy or grateful, it’s even worse than the goalkeeper’s work. Working with losses fosters a risk-seeking attitude: you are likely to risk more for a total defence, so ignoring sure solutions against minor threats.
- Bear in mind that it’s really easy to overestimate small probabilities. This can lead you to invest in solutions that protect against striking but not prevalent threats. You can invest in APTs flashily named and at the same time forget that most of the attacks are carried out through common and not at all glamourous methods: phishing, webpages injections, traditional recompiled and repacked malware against which there are patches… Anyway, more of the same, that is far removed from “advanced”, “intelligent” or “sophisticated”. For sure, they are highly persistent, since the most successful threats are the oldest ones. Nihil novum sub sole.
- Don’t fall into the diminishing sensitivity trap. The S curve gets flatter. This means that a first incident causes a higher impact than the tenth one of the same magnitude. Each attack “will hurt” less than the previous one, losses being the same. The organisation gets desensitized. For this reason, acting from the first incident is so important, since the organisation is raw. The more time you take to react, even if the incident occurs again, the less striking it will be considered. After all, here we are, right?
- For defenders, an attack is successful or not, and the result is all or nothing. If an attack is 1% successful, you are not 99% protect since, in case of the attack being successful, you will have succumbed to 100%. A successful and serious incident will radically move your point of reference to the losses. You won’t feel as safe as before the incident. Therefore, the organization will probably invest in an attempt to bring the point of reference back to its initial state. A change in the point of reference will cause your sensitivity to change when dealing with the same incidents: if this point is lowered, then a terrible incident for you before will make you feel indifferent now, and the other way around. It’s important to check the point of reference by using all the metrics and measures at your disposal.
No matter how hard you try, your will never take ideal or perfect decisions. You will be obligated to face countless restraints in terms of resources (both economic and personal), culture, legislation, etc. Moreover, your own behaviour against risk must be brought into the equation, such behaviour being influenced by a number of factors of which YOU ARE NOT EVEN AWARE.With this entry, I want to help you to become more aware of some of these factors. Keep them in mind for your future security decisions. People tend to accept an incremental profit in security instead of the probability of a greater profit. In the same way, they tend to take the risk of a big loss instead of accepting the certainty of a small one, what about you?
Gonzalo Álvarez de MarañónInnovation and Labs
(ElevenPaths)