Did you know that Machine Learning is already being used to help doctors identify rare genetic disorders by analysing images of people´s faces?
The quantity of genetic illnesses is so overwhelming that in some cases it’s difficult to reach a definite diagnosis because, although each one has varied characteristics that differentiate them form one another, a lot of the time the symptoms present themselves in a similar way.
A magazine Nature Medicine has just published an article about an app for smartphones, Face2Gene, that is capable of identifying different facial features in photos that are derivative of certain genetic and neurological disorders.
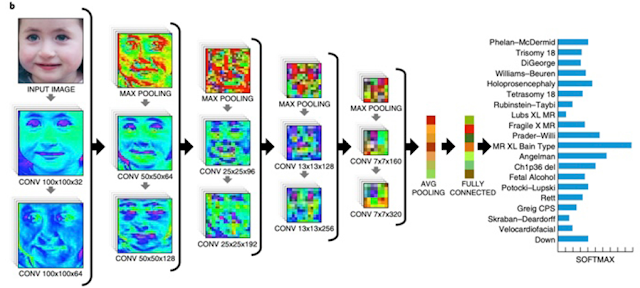
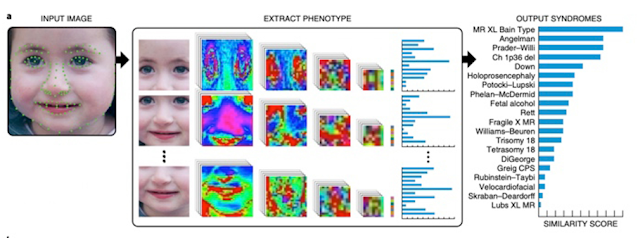
This technology analyses the patient photo using descriptive facial mathematics that are shared with the gestalt of different syndromes. It then quantifies their similarity and offers a prioritised list of syndromes with a similar morphology.
Face2Gene was created by the FDNA, one of the leading companies in artificial intelligence applications for genetic diagnosis. Their initial objective was to create an app that was capable of identifying syndromes such as Angelmann, Noonan and Cornelia de Lange, three rare genetic disorders with distinct facial characteristics.

To do this, they fed the algorithm more than 17,000 images of diagnosed cases that included 216 different syndromes, which resulted in exceptional diagnosis results.
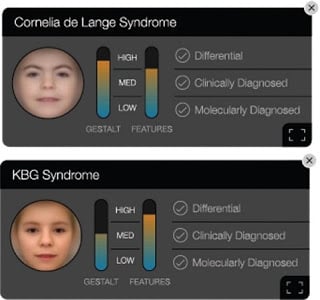
This app does not pretend to provide definitive diagnoses. Doctors use it for a second opinion or even as a point of reference when they don’t know how to interpret a patient’s symptoms involving rare genetic disorders.
Thus, Artificial Intelligence acts as a way of achieving a more accurate diagnosis, a way of saving time, and as a way of saving costs associated with ´amplified range´ genetic testing that will no longer be a necessary means of radically limiting the list of possible diagnoses.
In order for Face2Gene to be able to offer strong diagnoses, it needs data. The good news is that health professionals agreed to upload patient photos to the application (that now has over 150,000 available images on its database), which has improved the programs precision.
It´s fundamentally important that a lot of data is shared in order to avoid racial biases and to achieve a balanced representation of different populations so people all around the world can be treated.
Early diagnosis is crucial for these types of illnesses. It is amazing to think that one day soon we may hear that paediatricians and geneticists are able to use these kinds of apps with the same ease with which they use their stethoscope.
Don’t miss out on a single post. Subscribe to LUCA Data Speaks.