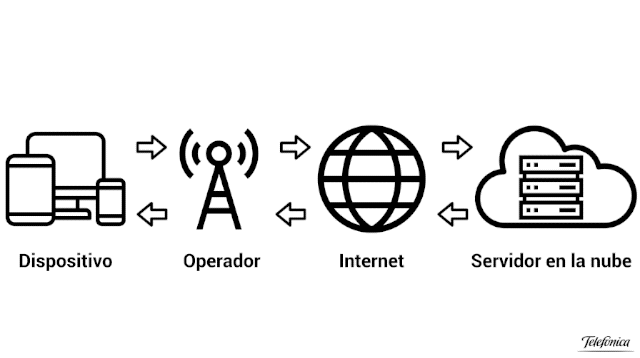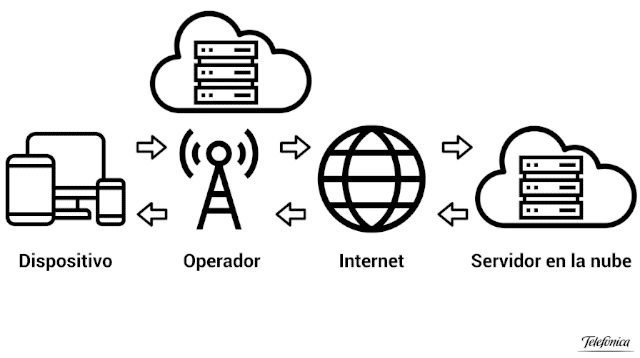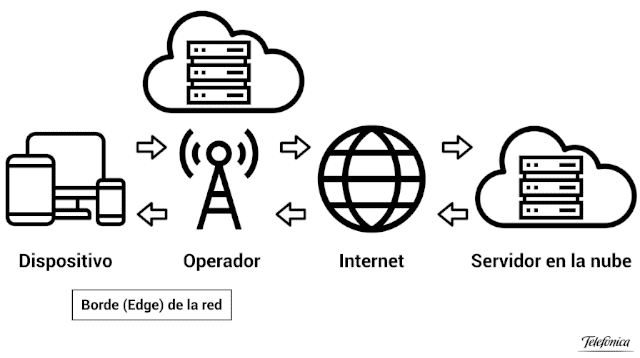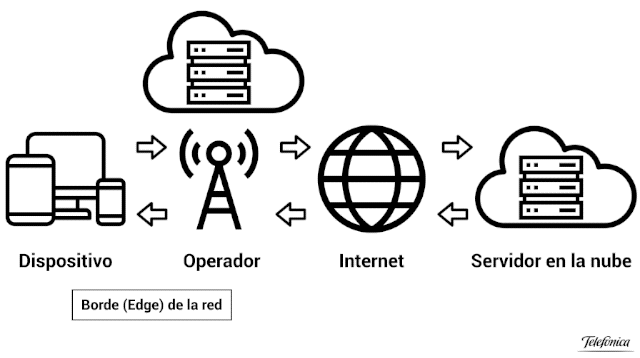
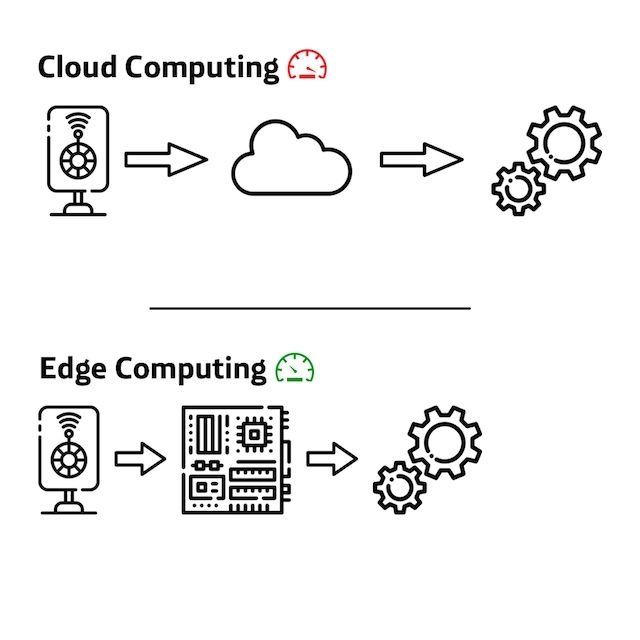
One of the companies’ biggest dreams when it comes to communicating their advertising campaigns, offers and services is to be able to adapt these communications to the profile of the people who are currently receiving these advertising messages.
In the online world, for many years, browsing data, cookies, etc. have been used to personalise the advertisements displayed on websites; two people with different profiles accessing the same website will not see the same advertising. In some cases, although the advertising is the same, the presentation is different to make it more attractive.
We are affected by this type of strategies on a daily basis, for example, in some streaming content platforms, the same series has different thumbnails that highlight different features of the series, making it attractive to people with different interests.
In the first article of the AI of Things series, we talked about the two main pillars of transforming the physical world, sensorisation and data exploitation.
In this article we are going to look at how knowledge of customer profiles can have an impact on business through communication.
How can I adapt my campaigns?
This article does not have a technical nature, but we must first define the technological scenario that will allow us to have an impact on our business. There are currently several technologies that we can deploy in our physical space to obtain information about our customers, the most important include:
- Videoanalytics: it allows, through cameras and always in compliance with GDPR regulations, to obtain information on the number of customers, various parameters such as age, gender, whether they come alone or with their family, movement within the space, etc.
- Big Data: Aggregate data obtained from various data sources that give us aggregated profiles with demographic and socio-economic data.
- WiFi Trackers: it allows mobile devices with open WiFi to know the number of these customers and how long they stay, among other data.
- Proximity marketing: the customer has an app installed on their mobile device, which may or may not contain a loyalty card. Through WiFi or Beacons we can know when the customer is in the shop and impact them with messages based on their purchase history, etc.
- Audience measurement: by installing cameras on dynamic marketing screens, we have the ability to understand the audiences for content and their demographic profile.
These technologies will be deployed on the physical space based on the objectives that are set and will be linked to a dynamic marketing platform, which allows the management of the content that is broadcast on the screens that are deployed in the different points of sale.
Campaigns carried out with dynamic marketing, whether on screens or on customers’ mobile devices, have a greater impact and a higher recall rate than campaigns carried out on traditional media. This is due to the channel itself and to the fact that the content is designed specifically for this media.
Until recently, these campaigns were scheduled according to start and end dates, as well as days and times of the week; based on empirical knowledge of observation of managers, strategic targets of the company and the like. This was already an improvement over static campaigns, but still far from the adaptive capabilities of online campaigns.
Technologies and strategies to reach the right audience
In the last year and a half, thanks to the technologies mentioned above, the ability to combine strategic programming of content with the ability to generate rules to change content based on the audience currently in your space has begun to develop, so that the content offered is the most appropriate to the profiles of the audience.
The implications that this has on the business is greater than it may seem and affects various aspects, always with the aim of increasing the conversion rate and improving the experience in the space.
Showing the right product to the profile of the customers will increase the conversion into sales of that product, while the presentation of tactical offers helps to have a higher percentage of impulse purchases, bearing in mind that we are carrying out the campaign in the place where the purchase is going to be made.
The above is already a tremendous step forward compared to static campaigns, but it still requires an analysis of the data and, depending on what is seen in terms of customer trends, product targeting, time of year, etc., a strategy must be designed and the content to be reproduced must be chosen to ensure that the conditions set are met.
Where are we heading?
The future we are envisioning at Telefonica Tech IoT & BD is based on our own platform of intelligent spaces, spotdyna and the new capabilities of Big Data and analytics to develop an algorithm within the AI of Things platform with the ability to orchestrate the content to be broadcast at all times on the dynamic marketing platform, based on all this data and applying an exhaustive labelling of the content where various characteristics of the content are indicated both objectively and subjectively.
These algorithms will take into account various inputs that will include data such as the day of the year, the time, the weather, what has happened in the past in terms of sales on days with a similar profile, analysis of customers who are currently in the space, forecasts for the future, etc.
With this we will be able to simplify and make the content programming process more efficient, where what we would have to do is to tag the content and make it available as a pool, where the algorithm with automatic learning would be fed with all the sensors, big data and other environmental data to make the best decision and also be able to know the impact of the decision to follow the learning process, being able to make better and better decisions, offering content with offers and services better adapted to the audience and environment, achieving better conversion rates in sales.
The path of evolution is set and we are taking the first steps of this new paradigm.
If you want to know more applications of the fusion of the Internet of Things and Artificial Intelligence, or what we call AI of Things, you can read other articles of the series: