Modern browsers usually have an antiXSS filter, that protects users from some of the consequences of this kind of attacks. Normally, they block cross site scripting execution, so the “injected” code (normally, JavaScript or HTML) is not executed inside victim’s browser. Chrome calls this filter XSSAuditor. Our coworker Ioseba Palop discovered a way to bypass it months ago. Since it is already resolved in the “main” version of Chrome, we are publishing technical details now.
In ElevenPaths, we just found a way to evade XSS filter in Chrome. This means, if the victim visits a website with an XSS problem that an attacker is trying to take advantage of, it would not be fully protected. The bug is based on a misuse of srcdoc attribute of IFRAME tag, included in HTML5 definition. To perform an XSS attack on Google Chrome Browser using this bug, the website must include an IFRAME and must be able to read any attribute of this element from HTTP parameters (GET/POST) without applying any charset filter. Then, in the IFRAME parameter, the srcdoc attribute may be included with JavaScript code. Chrome cannot filter it and will be executed.
To reproduce the PoC, there should be a webpage with some IFRAME tag like this:


And an HTML injection on src parameter would be:

Now the victim should visit: http://demofaast.elevenpaths.com:9002/xssbypass/iframebypass.php?iframe=%22srcdoc=%22%3Cscript%3Ealert(‘Bypass%20message’)%3C/script%3E
and XSS filter will fail and let the script run.
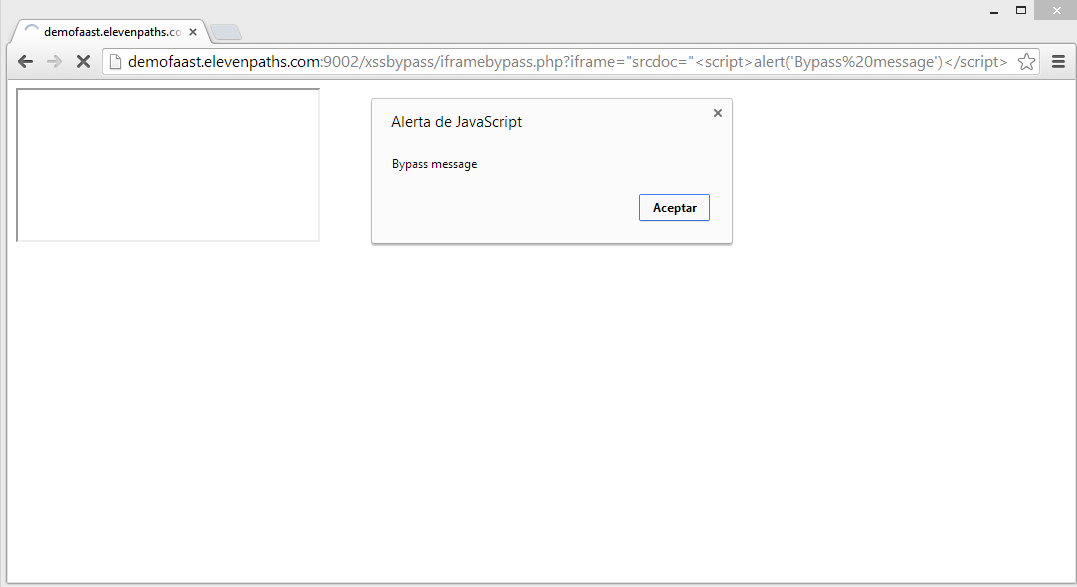
Google derived this to Chromium, who does not treat this bypasses as a security problem, since XSSauditor is considered a second defense line.
The problem was reported in October, the 23rd. They fixed it two days later, making XSSAuditor catch reflected srcdoc properties even without an “IFRAME” tag injection. Chrome has just fixed it in recent 32.0.1700.76 version.
Some other bug
A few weeks ago, in this post, someone took our PoC as an inspiration and developed another way of bypassing the filter. This one is still not fixed. The trick is to inject an opening “script” tag inside a parameter that is written directly in the HTTP request output stream. This is, without filtering any character just as our case. In this writing there should be content inside scripts tags that belongs to the web itself.

The browser will include our injection (remember, without closing the tag), omit the “script” opening tag from the web itself, and now, use the closing one from the web to create a well formed script and execute it… this is the bypass.

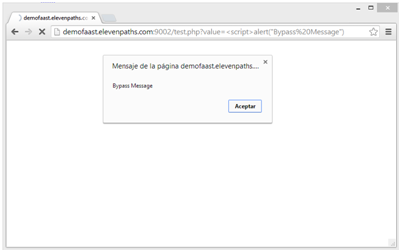
So this is the effect in this PoC we uploaded: http://demofaast.elevenpaths.com:9002/xssbypass/scriptbypass.php?value=%3Cscript%3Ealert%28%22Bypass%20Message%22%29
Safari, still vulnerable
Safari for Mac and iPhone is vulnerable as well. They confirmed our email, and told us they were working on it. And seems that they still are, since the program is still vulnerable. Everytime we have tried to contact back with them again, they reply back telling there is no news, but they are working on it. Internet Explorer filters it with its own filter, and Firefox does not implement an XSS filter by itself.